Case
I need a process to create Azure Data Lake containers throughout my DTAP environment of my Azure Data Platform. Manually is not an option because we want to minimize owner and contributor access to the Data Lake of acceptance and production, but Synapse and Data Factory don't have a standard activity to create ADL containers. How to automatically create Azure Data Lake Containers (and folders) ?
 |
| Storage Account (datalake) containers |
SolutionAn option is to use a PowerShell script that is executed by the
Custom activity in combination with an Azure Batch service. Or an Azure Automation runbook with the same PowerShell script that is executed by a Web(hook) activity.
However since you probably don't need create new containers during every (ADF/Synapse) pipeline run, we suggest to do this via an Azure Devops Pipeline as part of your CICD proces with the same PowerShell script. You could either create a separte CICD pipeline for it or integrate it in your Synapse or ADF pipeline.
The example below creates containers and optionaly also folders and subfolders within these container. Synapse and Data Factory will create folders with forexample the Copy Data activity
1) Repos folder structure
For this example we use a CICD folder in the repos with subfolders for PowerShell, YAML and Json.
 |
| Repos folder structure |
2) JSON config
Because we don't want to hardcode the containers and folders we use a JSON file as input for the PowerShell script. This JSON file is stored within the JSON folder of the DevOps Repository. We use the same JSON file for the entire environment, but you can ofcourse create a separate file for each environment if you need for example different containers on production. Our file is called config_storage_account.json
The folder array in this example is optional and when left empty no folders will be created. You can create subfolders within folders by separating them with a forwardslash.
{
"containers": {
"dataplatform":["folder1","folder2/subfolder1","folder2/subfolder2"]
, "SourceX":["Actual","History"]
, "SourceY":["Actual","History"]
, "SourceZ":[]
}
}
3) PowerShell code
The PowerShell script called SetStorageAccounts.ps1 is stored in the PowerShell folder and contains three parameters:
- ResourceGroupName - The name of the resource group where the storage account is located.
- StorageAccountName - The name the storage account
- JsonLocation - The location of the json config file in the repos (see previous step)
It checks the existance of both the config file and the storage account. Then first loop through the containers from the config and within the container loop it loops through the folders of that specific container. For container names and folderpaths it does some small corrections for often made mistakes.
Note that the script will not delete containers and folders (or set authorizations to them). This is of course possible, but make sure to test this very thoroughly and even with testing a human error in configuring the config file is easy to make and could cause lots of data lose!
# This PowerShell will create the containers provided in the JSON file
# It does not delete of update containers and folders or set authorizations
param (
[Parameter (Mandatory = $true, HelpMessage = 'Resource group name of the storage account.')]
[ValidateNotNullOrEmpty()]
[string] $ResourceGroupName,
[Parameter (Mandatory = $true, HelpMessage = 'Storage account name.')]
[ValidateNotNullOrEmpty()]
[string] $StorageAccountName,
[Parameter (Mandatory = $true, HelpMessage = 'Location of config_storage_account.json on agent.')]
[ValidateNotNullOrEmpty()]
[string] $JsonLocation
)
# Combine path and file name for JSON file. The file name is hardcoded and the
# same for each environment. Create an extra parameters for the filename if
# you need different files/configurations per environment.
$path = Join-Path -Path $JsonLocation -ChildPath "config_storage_account.json"
Write-output "Extracting containernames from $($path)"
# Check existance of file path on the agent
if (Test-Path $path -PathType leaf) {
# Get all container objects from JSON file
$Config = Get-Content -Raw -Path $path | ConvertFrom-Json
# Create containers array for looping
$Config | ForEach-Object {
$Containers = $($_.containers) | Get-Member -MemberType NoteProperty | Select-Object -ExpandProperty Name
}
# Check Storage Account existance and get the context of it
$StorageCheck = Get-AzStorageAccount -ResourceGroupName $ResourceGroupName -Name $StorageAccountName -ErrorAction SilentlyContinue
$context = $StorageCheck.Context
# If Storage Account found
if ($StorageCheck) {
# Storage Account found
Write-output "Storage account $($StorageAccountName) found"
# Loop through container array and create containers if the don't exist
foreach ($container in $containers) {
# First a little cleanup of the container
# 1) Change to lowercase
$container = $container.ToLower()
# 2) Trim accidental spaces
$container = $container.Trim()
# Check if container already exists
Write-output "Checking existence of container $($container)"
$ContainerCheck = Get-AzStorageContainer -Context $context -Name $container -ErrorAction SilentlyContinue
# If container exists
if ($ContainerCheck) {
Write-Output "Container $($container) already exists"
}
else {
Write-Output "Creating container $($container)"
New-AzStorageContainer -Name $container -Context $context | Out-Null
}
# Get container folders from JSON
Write-Output "Retrieving folders from config"
$folders = $Config.containers.$container
Write-Output "Found $($folders.Count) folders in config for container $($container)"
# Loop through container folders
foreach ($folder in $folders) {
# First a little cleanup of the folders
# 1) Replace backslashes by a forward slash
$path = $folder.Replace("\","/")
# 3) Remove unwanted spaces
$path = $path.Trim()
$path = $path.Replace("/ ","/")
$path = $path.Replace(" /","/")
# 3) Check if path ends with a forward slash
if (!$path.EndsWith("/")) {
$path = $path + "/"
}
# Check if folder path exists
$FolderCheck = Get-AzDataLakeGen2Item -FileSystem $container -Context $context -Path $path -ErrorAction SilentlyContinue
if ($FolderCheck) {
Write-Output "Path $($folder) exists in container $($container)"
} else {
New-AzDataLakeGen2Item -Context $context -FileSystem $container -Path $path -Directory | Out-Null
Write-Output "Path $($folder) created in container $($container)"
}
}
}
} else {
# Provided storage account not corrrect
Write-Output "Storageaccount: $($StorageAccountName) not available, containers not setup."
}
} else {
# Path to JSON file incorrect
Write-output "File $($path) not found, containers not setup."
}
4) YAML file.
If you integrate this in your existing
Data Factory or
Synapse YAML pipeline then you only need to add one
PowerShell step. Make sure you have a checkout step to copy the config and powershell file from the repository to the agent. You may also want to add a (temporary)
treeview step to check the paths on your agent. This makes it easier to configure paths within your YAML code.
parameters:
- name: SerCon
displayName: Service Connection
type: string
- name: Env
displayName: Environment
type: string
values:
- DEV
- ACC
- PRD
- name: ResourceGroupName
displayName:
type: string
- name: StorageAccountName
displayName:
type: string
jobs:
- deployment: deploymentjob${{ parameters.Env }}
displayName: Deployment Job ${{ parameters.Env }}
environment: Deploy to ${{ parameters.Env }}
strategy:
runOnce:
deploy:
steps:
###################################
# 1 Check out repository to agent
###################################
- checkout: self
displayName: '1 Retrieve Repository'
clean: true
###################################
# 3 Show environment and treeview
###################################
- powershell: |
Write-Output "Deploying Synapse in the ${{ parameters.Env }} environment"
tree "$(Pipeline.Workspace)" /F
displayName: '2 Show environment and treeview Pipeline_Workspace'
###################################
# 3 Create containers in datalake
###################################
- task: AzurePowerShell@5
displayName: '3 Create data lake containers'
inputs:
azureSubscription: ${{ parameters.SerCon }}
scriptType: filePath
scriptPath: $(Pipeline.Workspace)\s\CICD\PowerShell\SetStorageAccounts.ps1
scriptArguments:
-ResourceGroupName ${{ parameters.ResourceGroupName }} `
-StorageAccountName ${{ parameters.StorageAccountName }} `
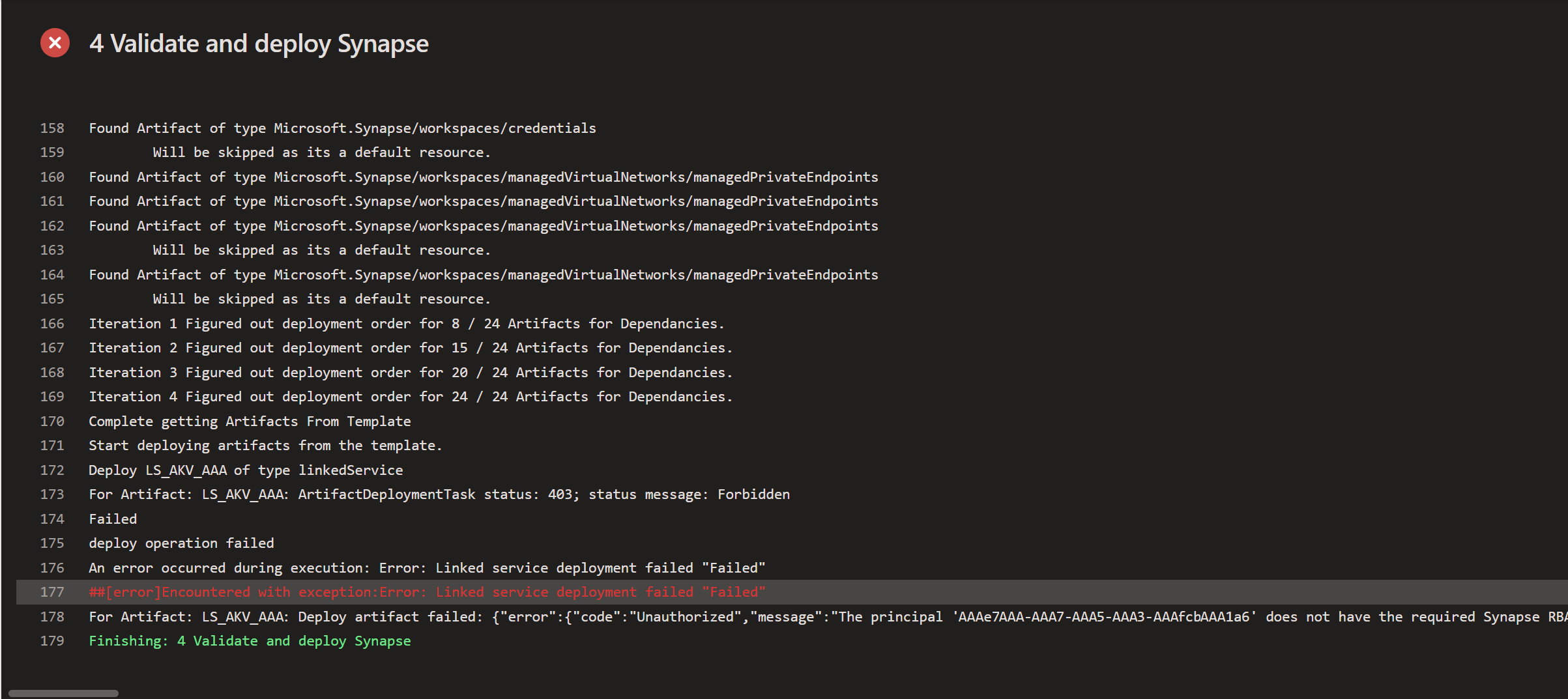
-JsonLocation $(Pipeline.Workspace)\s\CICD\Json\
azurePowerShellVersion: latestVersion
pwsh: true
5) The resultNow it's time to run the YAML pipeline and check the Storage Account to see wether the containers and folders are created.
 |
| DevOps logs of creating containers and folders |
 |
| Created data lake folders in container |
ConclusionIn this post you learned how to create containers and folders in the Storage Account / Data Lake via a little PowerShell script and a DevOps pipeline, but you can also reuse this PowerShell script in for the mentioned alternative solutions.
Again the note about also deleting containers and folders. Make sure to double check the code, but also the procedures to avoid human errors and potenially loose a lot of data. You might want to
setup soft deletes in your storage account to have a fallback scenario for screwups.