Case
I have one big Power BI dataset with multiple source tables and one of those source tables is refreshed once every hour and all the other tables are only refreshed once a day. How can refresh only specific tables within my Power BI dataset via an ADF or Synapse pipeline?
 |
| Using XMLA enpoints in Power BI |
Solution
To accomplish this you need the XMLA enpoints in Power BI. Those XMLA enpoints provide access to the Analysis Services engine in Power BI giving you extra options for your dataset like only refreshing a single table (or a couple of tables).
However, XMLA enpoints are only availble for premium workspaces. So you either need Power BI premium (capacity) or Power BI premium per user. This doesn't work for Power BI PRO.
1) Enable XMLA endpoints
- Log in to PowerBI.com
- Click on the gear icon in the top right corner
- Choose Admin Portal
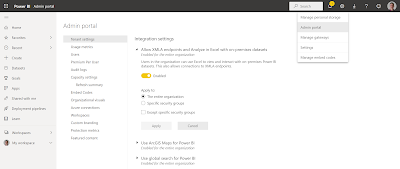
- Click on Tenant settings in the Admin portal menu. If you don't see that option then you don't have the PBI admin role
- Scrole down to Integration settings
- Expand 'Allow XMLA endpoints and Analyze in Excel with on-premises datasets'
- Check whether it is enabled for either The entire organization or Specific security groups. If it is set to Specific security groups make sure that your user and the Service Principal or the Managed Identity of ADF/Synapse is in that group.
 |
Allow XMLA endpoints and
Analyze in Excel with on-premises datasets |
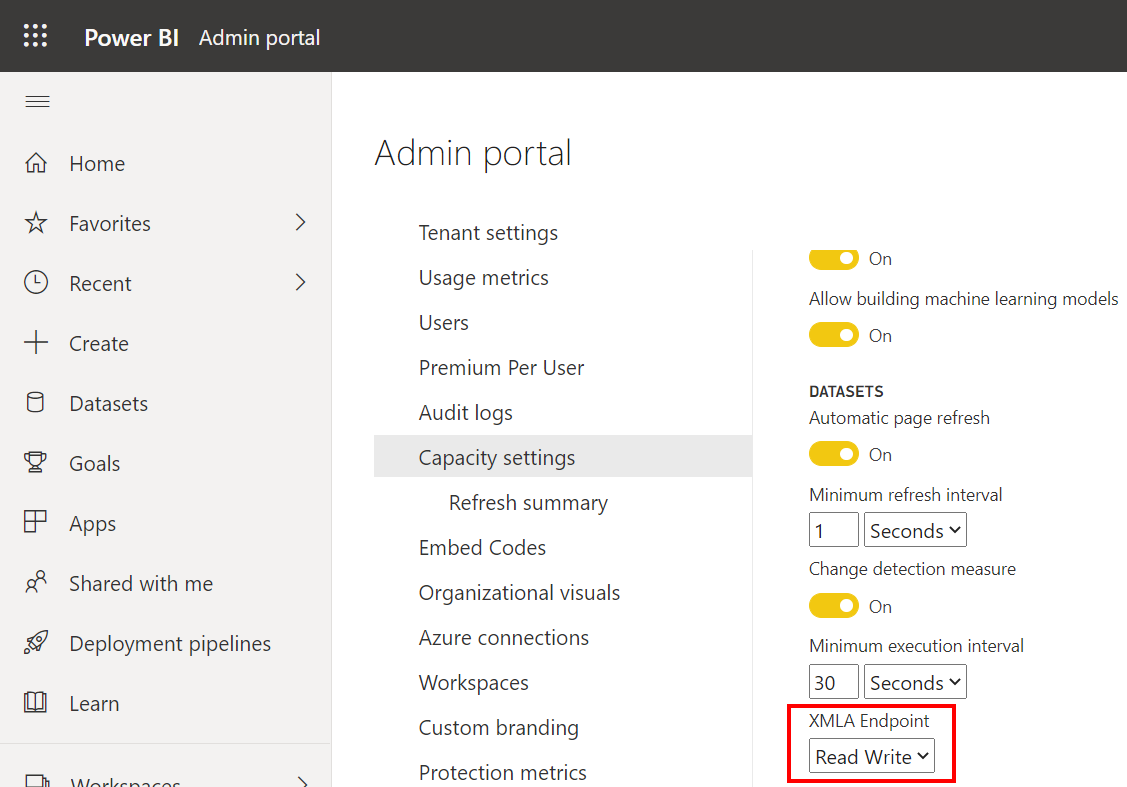
2) Set to Read-Write
Depending or the premium license type you go to Premium Per User or to Capacity settings in the same Admin portal menu. And if you have multiple Capacities then first go to the specific Capacity.
- In the Admin portal go to Premium Per User or to Capacity settings (depending on your license)
- Locate the XMLA Endpoint setting and set it to Read Write
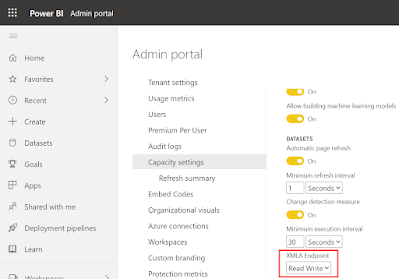 |
| XMLA endpoints for Premium Capacity |
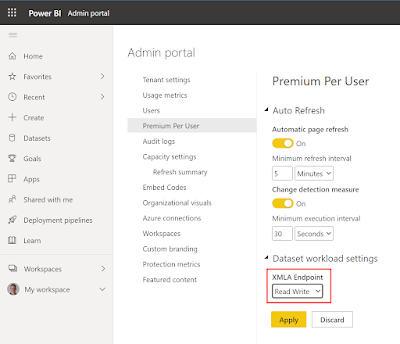 |
| XMLA endpoints for Permium per user |
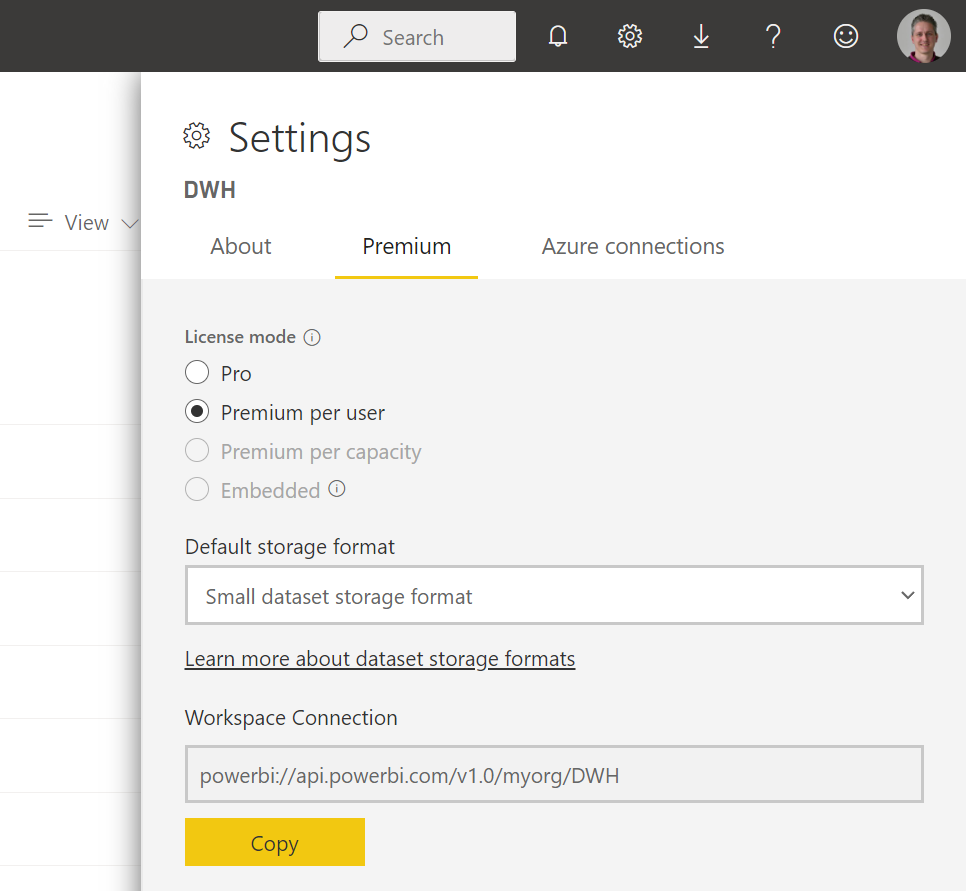
3) Premium workspace
Now go to the Power BI Workspace where your dataset is located and make sure the workspace is a Premium workspace. You can change it in the Settings in the upper right corner.
4) Create JSON message
Now go to your ADF or Synapse pipeline that refreshes the Power BI dataset where you either use a
Service Principal or a
Managed Identity to access Power BI. All those steps are described in details in those two posts.
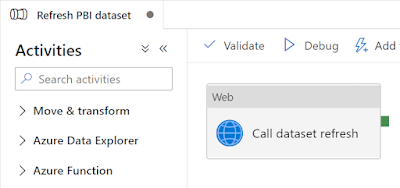 |
| Web Activity to refresh a Power BI dataset |
The body of this Web Activity contains options for refreshing the dataset. Our basic example only contained an option to skip notifications: {"notifyOption":"NoNotification"}. This message can also contain
settings to refresh only certain tables. Check DatasetRefreshObjects and DatasetRefreshType in the documentation and create a JSON messages like this where we refresh only the data of two tables: myFact and myDim.
{"notifyOption":"NoNotification"
,"objects":"[{"table":"myFact"},{"table":"myDim"}]"
,"type":"DataOnly"}
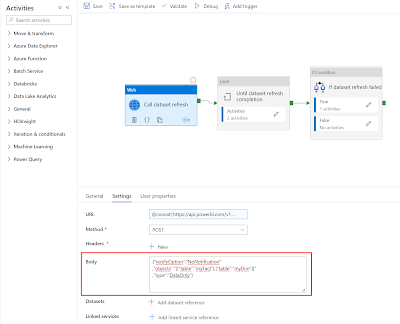 |
| Refresh specific tables in a PBI dataset |
5) Create JSON message via SQL
If you want to make that a little more flexible then you can put a Lookup activity in front of it that gets the tables from query like this:
SELECT CONVERT(VARCHAR(MAX),
(SELECT [table]
FROM [META].[DatasetContinuousRefresh]
WHERE Active = 1
FOR JSON PATH)
) as body
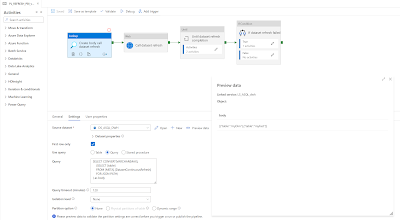 |
| Lookup activity to get table names in a JSON output |
Instead of the hardcoded body in the Web activity you can create something more dynamic with an expression like:
@concat('{"notifyOption":"NoNotification"'
,if(pipeline().parameters.ContinuousLoad,concat(',"objects":"',activity('Create body call dataset refresh').output.firstRow.body,'"'),'')
,',"type":"DataOnly"}')
The entire pipeline to refresh a Power BI dataset via its name (instead of the ID) looks something like this:
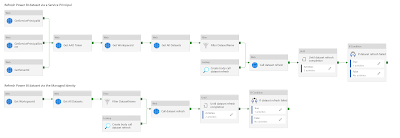 |
| The complete refresh PBI dataset pipeline |
Please check the previous blog posts for all the details
Conclusions
In this post we showed you how to refresh only a single table or just a couple of tables within a Power BI dataset. This could save you a lot of refresh time if you don't want to refresh all tables each and every time. The only downside is that Power BI PRO is not enough and you need access to the Power BI admin portal to set the XMLA settings.
thx to colleague
Hans Timmerman for helping.