I like the data versioning of the Delta Tables and I know how to get data from different versions, but how can I combine that in one query to get for example the changes during a year to create a nice fact table about certain changes.
 |
| Change Data Feed in Synapse |
Solution
Change Data Feed (CDF) is still a bit new. The currently supported Delta Lake version in the Synapse workspace is 2.2.0. This version does not yet not support CDF for SQL queries. This shoud be available in Delta Lake 2.3.0 according to the release documentation. Luckily you can already use PySpark to get this information.
 |
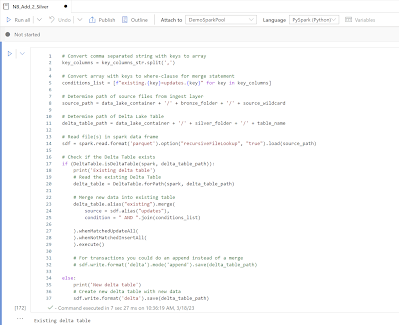
| Current Delta Lake version in Synapse |
1) Enable Change Data Feed
First you have to enable the Change Data Feed option on your Delta table. From that point in time you can use CDF. The property is called enableChangeDataFeed.
You can alter your existing tables with an Alter statement
%%sql ALTER TABLE silver.Cities SET TBLPROPERTIES (delta.enableChangeDataFeed = true);For new Delta Tables you can also do this in the Create Table command.
%%sql CREATE TABLE Silver.Cities (Id INT, City STRING, Population INT) TBLPROPERTIES (delta.enableChangeDataFeed = true);
And if you used the PySpark code from our previous post, then you can add an option just in front of the save.
sdf.write.format('delta').option("delta.enableChangeDataFeed", "true").save(delta_table_path)
To check whether it is enabled on your Delta Table you can use the following command.
%%sql SHOW TBLPROPERTIES silver.cities
 |
| CDF is enabled |
2) Check available data versions
Now that we have the Change Data Feed option available, lets check which data versions we have with the DESCRIBE HISTORY command. In the first example you will see that CDF is enabled after table creation in the second version (1). This means you can not include the first version (0) in the CDF command.
You will get an error if you set the range wrong while getting CDF info:
AnalysisException: Error getting change data for range [0 , 4] as change data was not
recorded for version [0]. If you've enabled change data feed on this table,
use `DESCRIBE HISTORY` to see when it was first enabled.
Otherwise, to start recording change data, use `ALTER TABLE table_name SET TBLPROPERTIES
(delta.enableChangeDataFeed=true)`.
 |
| CDF available from version 1 |
In the second example it was enabled during the Delta table creation and therefore CDF is available from the first version (0).
 |
| CDF available from version 0 |
3) Query CDF data
When you query the CDF data you will get some extra columns:
- _change_type: showing what action was taken to change the data - insert, update_preimage, update_postimage and delete
- _commit_version: showing the version number of the data
- _commit_timestamp: showing the timestamp of the data change
If you want particular versionnumbers when getting the data, then you can use startingVersion and endingVersion as an option while reading the data. Only startingVersion is also permitted.
%%pyspark
df = spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 0) \
.option("endingVersion", 5) \
.table("Silver.cities")
display(df.sort("City","_commit_version"))
 |
| Filter CDF on version numbers |
Probably more useful is to query date ranges, then you can use startingTimestamp and endingTimestamp as an option. Only startingTimestamp is also permitted.
%%pyspark
df = spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingTimestamp", '2023-03-26 11:07:23.008') \
.table("Silver.cities")
display(df.sort("City","_commit_version"))
 |
| Filter CDF on timestamps |
If you want to use the new column _commit_timestamp from the next record to create a new column called end_timestamp in the current record, then you need to play with the lead() function (just like in TSQL).
%%pyspark
from pyspark.sql.window import Window
from pyspark.sql.functions import lead
df = spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingTimestamp", '2023-03-26 11:07:23.008') \
.table("Silver.cities")
# Create window for lead
windowSpec = Window.partitionBy("City").orderBy("_commit_version")
# Remove update_preimage records, add new column with Lead() and then sort
display(df.filter("_change_type != 'update_preimage'")
.withColumn("_end_timestamp",lead("_commit_timestamp",1).over(windowSpec))
.sort("City","_commit_version"))
 |
| Create end_timestamp with lead function |
Conclusions
In this post you learned the basics of the Change Data Feed options in Synapse. This feature is available in Delta Lake 2.0.0 and above, but it is still in experimental support mode. For now you have to use PySpark instead of Spark SQL to query the data in Synapse.
Besides creating nice fact tables to show data changes during a certain periode this feature could also be useful to incremental load a large fact table with only changes from the silver layer. Creating audit trails for data changes over time could also be an interesting option. The CDF option is probably the most useful when there are not that many changes in a table.
In a later post, when Delta Lake 2.3.0 is available in Synapse, we will explain the Spark SQL options for CDF. Special thanks to colleagues Roelof Jonkers and Martijn Broeks for helping out.