Case
To turn of the Synapse triggers before deployment and turning them back of after deployment, we used a
PowerShell script for ADF that we rewritten for Synapse. However now there is a new activity available that avoids the use of scripting, but it is a bit hidden if you mainly use YAML for pipelines.
 |
| Azure Synapse Toggle Triggers Dev (Preview) |
Solution
If you go the release pipelines (not YAML, but the visual variant) and under add task search for Synapse then you will find the Synapse workspace deployment activity, but also the Azure Synapse Toggle Triggers Dev. It's already out there for a couple months but still preview (probably to busy with Fabric at the moment). For these tasks you need to add the
Synapse addon to Azure DevOps, but if you are already using the deployment task then you already have it. The postfix of the taskname is Dev, so it is to be expected that they will remove it once it is General Available.
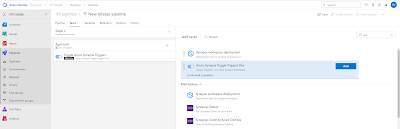 |
| Synapse Tasks |
Since we have a preference for YAML we need to know what the task name is and which properties are available. There is no YAML documentation available, but it you fill in the form in the release pipeline then you can view the YAML code. And by clicking on the circled i icon you will get some more info about the properties.
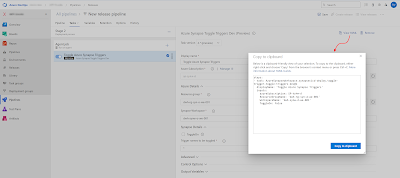 |
| View YAML code |
First the YAML code for toggling off all triggers which you need to do before deploying a new version of Synapse. With and without parameters.
steps:
- task: AzureSynapseWorkspace.synapsecicd-deploy.toggle-trigger.toggle-triggers-dev@2
displayName: 'Toggle Azure Synapse Triggers'
inputs:
azureSubscription: SP-synw-d
ResourceGroupName: 'dwh-synw-d-we-001'
WorkspaceName: 'dwh-synw-d-we-001'
ToggleOn: false
Triggers: '*'
- task: AzureSynapseWorkspace.synapsecicd-deploy.toggle-trigger.toggle-triggers-dev@2
displayName: 'Toggle Azure Synapse Triggers'
inputs:
azureSubscription: ${{ parameters.SerCon }}
ResourceGroupName: ${{ parameters.Synapse_ResourceGroupName }}
WorkspaceName: ${{ parameters.Synapse_WorkspaceName }}
ToggleOn: false
Triggers: '*'
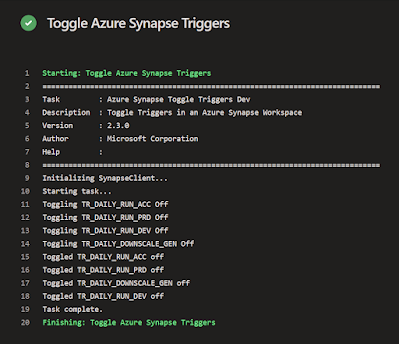 |
| Toggle all trigger OFF |
Then the same code but now for enabling certain triggers. Again with and without parameters.
steps:
- task: toggle-triggers-dev@2
displayName: 'Toggle Azure Synapse Triggers'
inputs:
azureSubscription: SP-synw-d
ResourceGroupName: 'dwh-synw-d-we-001'
WorkspaceName: 'dwh-synw-d-we-001'
ToggleOn: true
Triggers: 'TR_DAILY_RUN_DEV,TR_DAILY_DOWNSCALE_GEN'
- task: toggle-triggers-dev@2
displayName: 'Toggle Azure Synapse Triggers'
inputs:
azureSubscription: ${{ parameters.SerCon }}
ResourceGroupName: ${{ parameters.Synapse_ResourceGroupName }}
WorkspaceName: ${{ parameters.Synapse_WorkspaceName }}
ToggleOn: true
Triggers: '${{ parameters.Synapse_EnableTriggers }}'
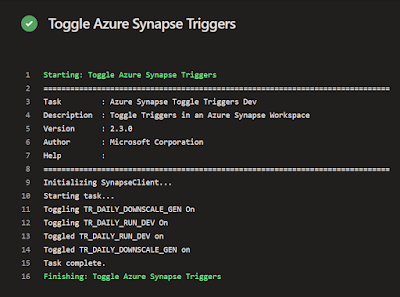 |
| Toggle specific triggers ON |
You can remove the long prefix in the task name and just keep
toggle-triggers-dev@2. Property ToggleOn set to 'false' means stop the triggers and 'true' means start the mentioned triggers. The triggers property shoud contain a '*' to stop/start everything, but you probably only want to enable certain triggers on each environment. In that case you can use 'trigger1,trigger2,trigger3' to do that, but without spaces around each comma. With extra spaces you will get an error that the trigger is not found. In the error message you can see the extra space in front of the trigger name.
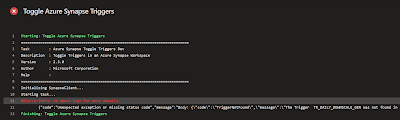 |
##[error]Refer to above logs for more details:
The Trigger TR_DAILY_DOWNSCALE_GEN was not found |
An other issue is that the Triggers property must be filled. If you have one environment where you don't want to start any of the triggers then you will get an error saying that the property is required. I would rather see a warning instead or an other user friendly solution that works with some of the YAML shortcomings.
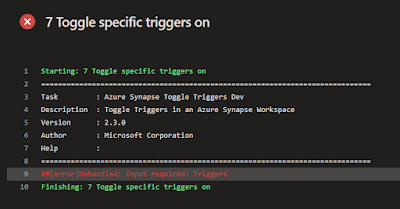 |
| ##[error]Unhandled: Input required: Triggers |
You can solve this by adding a YAML condition to the task where you check whether the list of triggers is empty. If it is, the task will be skipped. Unfortunately you
cannot use a parameter in a condition. The workaround is to read directly from a variable group:
- task: toggle-triggers-dev@2
displayName: 'Toggle Azure Synapse Triggers'
condition: ne(replace(variables.Synapse_EnableTriggers, ' ', ''), '')
inputs:
azureSubscription: ${{ parameters.SerCon }}
ResourceGroupName: ${{ parameters.Synapse_ResourceGroupName }}
WorkspaceName: ${{ parameters.Synapse_WorkspaceName }}
ToggleOn: true
Triggers: '${{ parameters.Synapse_EnableTriggers }}'
Alternatives
If you don't like that workaround there are two alternatives until Microsoft fixes the issue. You could use the OverrideParameters option to override the endTime property of a trigger during the Synapse deployment as
showed here for Data Factory or use a PowerShell activity to enable the triggers just like
for ADF. For this PowerShell option you need to create a PowerShell file in the repository under \CICD\PowerShell with the name SetTriggers.ps1 and the following code (Synapse version):
param
(
[parameter(Mandatory = $true)] [String] $WorkspaceName,
[parameter(Mandatory = $true)] [String] $ResourceGroupName,
[parameter(Mandatory = $true)] [string] $EnableTriggers,
[parameter(Mandatory = $false)] [Bool] $DisableAllTriggers = $true
)
Write-Host "Checking existance Resource Group [$($ResourceGroupName)]..."
Get-AzResourceGroup -Name $ResourceGroupName > $null
Write-Host "- Resource Group [$($ResourceGroupName)] found."
Write-Host "Checking existance Synapse Workspace [$($WorkspaceName)]..."
Get-AzSynapseWorkspace -ResourceGroupName $ResourceGroupName `
-Name $WorkspaceName > $null
Write-Host "- Synapse Workspace [$($WorkspaceName)] found."
#Getting triggers
Write-Host "Looking for triggers..."
$Triggers = Get-AzSynapseTrigger -WorkspaceName $WorkspaceName
Write-Host "Found [$($Triggers.Count)] trigger(s)"
# Checking provided triggernames, first split into array
$EnabledTriggersArray = $EnableTriggers.Split(",")
Write-Host "Checking existance of ($($EnabledTriggersArray.Count)) provided triggernames."
# Loop through all provided triggernames
foreach ($EnabledTrigger in $EnabledTriggersArray)
{
# Get Trigger by name
$CheckTrigger = Get-AzSynapseTrigger -WorkspaceName $WorkspaceName `
-Name $EnabledTrigger `
-ErrorAction Ignore # To be able to provide more detailed error
# Check if trigger was found
if (!$CheckTrigger)
{
throw "Trigger $($EnabledTrigger) not found in Synapse Workspace $($WorkspaceName) within resource group $($ResourceGroupName)"
}
}
Write-Host "- All ($($EnabledTriggersArray.Count)) provided triggernames found."
##############################################
# Disable triggers
##############################################
# Check if all trigger should be disabled
if ($DisableAllTriggers)
{
# Get all enabled triggers and stop them (unless they should be enabled)
Write-Host "Getting all enabled triggers that should be disabled."
$CurrentTriggers = Get-AzSynapseTrigger -WorkspaceName $WorkspaceName `
| Where-Object {$_.RuntimeState -ne 'Stopped'} `
| Where-Object {$EnabledTriggersArray.Contains($_.Name) -eq $false}
# Loop through all found triggers
Write-Host "- Number of triggers to disable: $($CurrentTriggers.Count)."
foreach ($CurrentTrigger in $CurrentTriggers)
{
# Stop trigger
Write-Host "- Stopping trigger [$($CurrentTrigger.Name)]."
try {
Stop-AzSynapseTrigger -WorkspaceName $WorkspaceName -Name $CurrentTrigger.Name > $null
} catch {
Write-Host "error code 1, but disabling trigger that already is disabled"
}
}
}
##############################################
# Enable triggers
##############################################
# Loop through provided triggernames and enable them
Write-Host "Enable all ($($EnabledTriggersArray.Count)) provided triggers."
foreach ($EnabledTrigger in $EnabledTriggersArray)
{
# Get trigger details
$CheckTrigger = Get-AzSynapseTrigger -WorkspaceName $WorkspaceName `
-Name $EnabledTrigger
# Check status of trigger
if ($CheckTrigger.RuntimeState -ne "Started")
{
try {
Write-Host "- Trigger [$($EnabledTrigger)] starting. This will take only a few seconds..."
Start-AzSynapseTrigger -WorkspaceName $WorkspaceName `
-Name $EnabledTrigger
} catch {
Throw "Error enabling trigger '$EnabledTrigger': $Error[0].Message"
exit 1
}
}
else
{
Write-Host "- Trigger [$($EnabledTrigger)] already started"
}
}
Then the YAML Code for after the deployment step:
- task: AzurePowerShell@5
displayName: 'Enabling triggers per environment'
inputs:
azureSubscription: ${{ parameters.SerCon }}
scriptType: filePath
scriptPath: $(Pipeline.Workspace)\s\CICD\PowerShell\Set_Triggers.ps1
scriptArguments:
-WorkspaceName ${{ parameters.Synapse_WorkspaceName }} `
-ResourceGroupName ${{ parameters.Synapse_ResourceGroupName }} `
-EnableTriggers "${{ parameters.Synapse_EnableTriggers }}"
azurePowerShellVersion: latestVersion
pwsh: true
ConclusionMicrosoft is introducing a very promising new DevOps task for Synapse that will make you CICD task much easier. Hopefully it will be G.A. soon and the small bugs will be solved. In the mean while you could use one of the alternatives if you don't want to use a preview version of the task.
An other solution for Microsoft could be to just add these options in the current deployment task since you always need to stop all triggers first and than start some of the triggers once the new version has been deployed. Is there a good reason to have these as two separate tasks in DevOps? Let it know in the comments below.
ADDITION
The new task toggle-triggers-dev@2 does not yet work with the new type of Azure Service Connection with Workload Identity federation. This will result in the following error: {"code":"U002","message":"The service connection authScheme WorkloadIdentityFederation is not supported by this task"}.
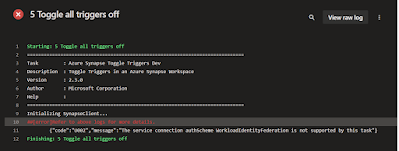 |
The service connection authScheme
WorkloadIdentityFederation is not supported by this task |






















